Referenzimplementierung im Forschungsprojekt KIVA
Die Referenzarchitektur soll den Betrieb auf der Deutschland-Plattform von GovTech Deutschland ermöglichen und ist so konzipiert, dass sie sich auch auf weitere cloud-agnostischen Plattformen übertragen lässt.
Die hier vorliegende Dokumentation beschreibt die Referenzarchitektur einer skalierbaren, sicheren und Open-Source-basierten KI-Plattform. Sowohl kurzfristige Erfolge als auch langfristige Erweiterbarkeit sollen erzielt werden. Der Fokus liegt auf der Integration bewährter Open-Source-Komponenten, der Implementierung robuster Sicherheitskonzepte und der Schaffung einer benutzerfreundlichen Plattform für verschiedene KI-Anwendungsfälle.
Developer-Dokumentation
Für technische Details zur Implementierung steht eine umfassende Developer-Dokumentation zur Verfügung. Diese enthält Installationsanleitungen, Konfigurationsbeispiele und detaillierte technische Beschreibungen aller Komponenten. → Zur KIVA Implementierungsdokumentation (Veröffentlichung 16.12.2025)
Ziel der Referenzimplementierung
Um die theoretischen Konzepte der Architektur zu validieren, wurde im Rahmen des Forschungsprojekts eine vollständige Referenzimplementierung aufgebaut und evaluiert. Diese Implementierung dient als Proof-of-Concept und Grundlage für die weitere Entwicklung einer produktionsreifen Plattform.
Umgesetzte Komponenten
KI-Inferenz-Engine (vLLM) kiva-vllm
Basiert auf: vLLM
vLLM ist eine hochoptimierte Inference-Engine speziell für große Sprachmodelle, die als Kernkomponente der KIVA-Plattform dient. Die Engine nutzt fortschrittliche Techniken wie PagedAttention für effizientes Speichermanagement und Continuous Batching für hohen Durchsatz. Sie unterstützt eine Vielzahl von Modellarchitekturen von verschiedenen Anbietern wie Meta (Llama) oder Mistral, bereitgestellt über Plattformen wie HuggingFace. Die implementierte Lösung ist vollständig GPU-beschleunigt und ermöglicht durch Tensor-Parallelisierung auch den Betrieb sehr großer Modelle über mehrere GPUs hinweg. vLLM stellt eine OpenAI-kompatible API bereit, wodurch bestehende Anwendungen ohne Anpassungen angebunden werden können.
LLM-Gateway kiva-llm-gateway
Basiert auf: LiteLLM (Fork von v1.74.4)
Das KIVA LLM Gateway basiert auf einem Fork von LiteLLM v1.74.4 (Stand zum Zeitpunkt der Referenzimplementierung) und fungiert als zentrale, modell-agnostische Zugriffsschicht für alle KI-Dienste. Es ermöglicht die einheitliche Ansprache verschiedener LLM-Anbieter (OpenAI, Azure OpenAI, Anthropic, HuggingFace, Ollama, lokale Modelle) über eine konsistente API. Das Gateway implementiert umfassende Sicherheitsfunktionen wie API-Key-Management, rollenbasierte Zugriffskontrolle, Rate Limiting und detailliertes Audit-Logging. Für Administratoren steht ein Web-Dashboard zur Verwaltung von Benutzern, Service-Accounts, Modellzugängen und Token-Limits zur Verfügung. Die Lösung bietet Load-Balancing zwischen mehreren Modell-Instanzen und automatische Fallback-Strategien bei Ausfällen.
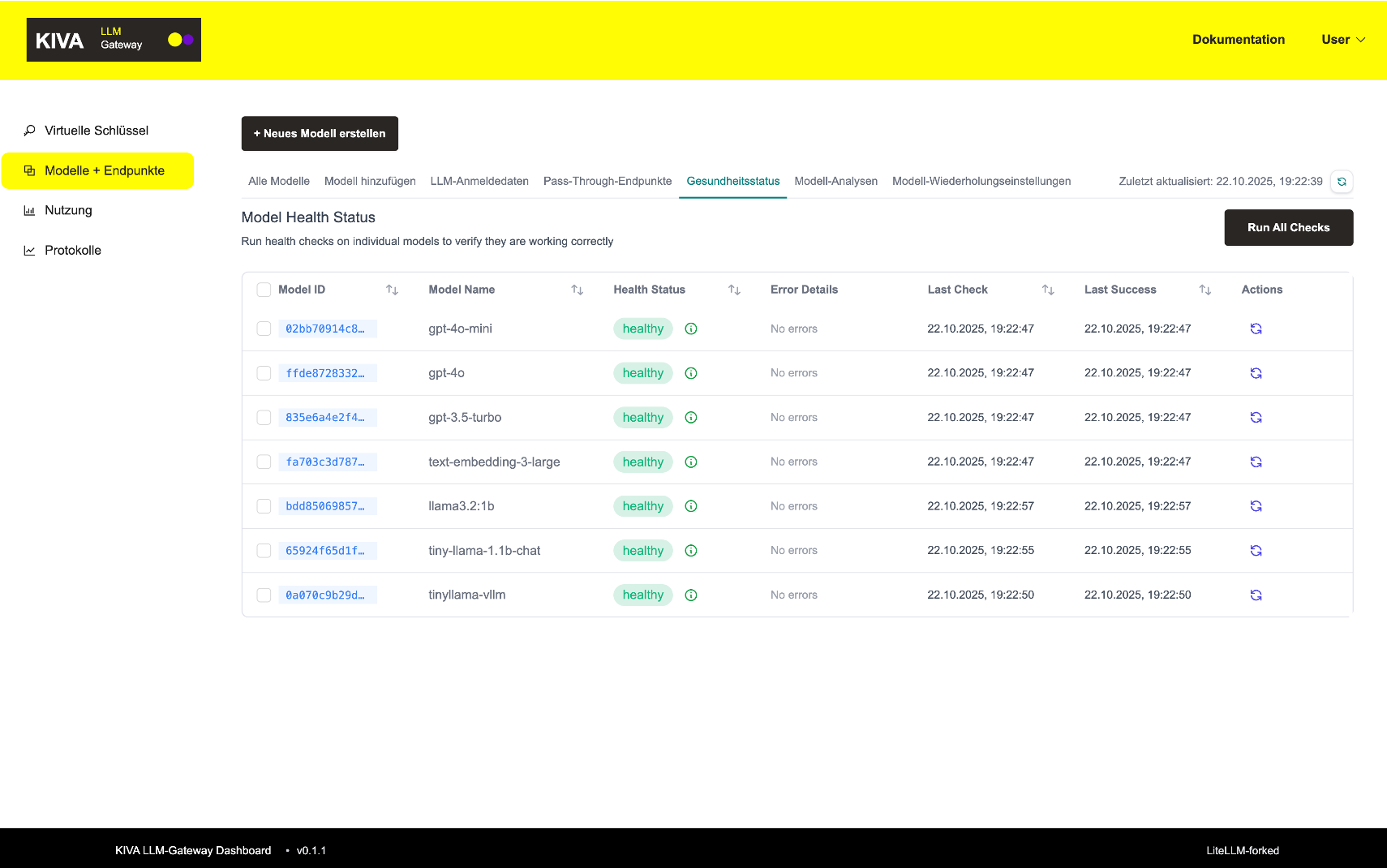
Wichtiger Hinweis zur Implementierung: Im Rahmen der Referenzimplementierung wurden bewusst nur die Minimalfunktionen des Gateways entwickelt. Die Administrationsoberfläche wurde nur in grundlegender Form umgesetzt. Für eine produktive Nutzung würde eine neu entwickelte, dedizierte Admin-UI empfohlen, die spezifisch auf die Anforderungen der Verwaltung zugeschnitten ist.
Automatisiertes Deployment kiva-infra
Die KIVA-Plattform implementiert ein modernes DevOps-Konzept mit vollautomatisierter CI/CD-Pipeline und GitOps-basiertem Deployment. Alle Microservices verfügen über eigene GitLab-CI-Pipelines, die automatisch Docker-Images bauen, Helm-Charts erstellen und diese in einer Container-Registry ablegen. Das Deployment unterstützt zwei Strategien: vollautomatisiertes Deployment direkt aus der Pipeline oder manuell gesteuertes Deployment über Helmfile für größere Kontrolle. Die Infrastruktur-Konfiguration folgt dem Infrastructure-as-Code-Prinzip, wobei alle Änderungen in Git versioniert und nachvollziehbar sind. Durch die Verwendung von Kubernetes und Helm ist die Lösung cloud-agnostisch und kann auf Azure, StackIT, Open Telecom Cloud, IONOS oder anderen Anbietern betrieben werden.
Überwachung und Monitoring kiva-monitoring
Das Monitoring-System basiert auf der bewährten Kombination aus Prometheus für Metriken-Erfassung und Grafana für Visualisierung. Es wurde speziell für die Überwachung von vLLM und LiteLLM konfiguriert und erfasst kontinuierlich Metriken wie Anfrage-Latenzen, Token-Durchsatz, GPU-Auslastung und Fehlerraten. Vorkonfigurierte Grafana-Dashboards bieten einen sofortigen Überblick über den Systemzustand und die Performance der KI-Modelle. Das System beinhaltet intelligente Alerting-Rules, die proaktiv bei Anomalien wie hoher Latenz, steigenden Fehlerraten oder Ressourcenengpässen warnen. Alle Monitoring-Komponenten sind als Helm-Charts paketiert und können einfach in bestehende Kubernetes-Umgebungen integriert werden.
Lizenz-Compliance kiva-licensescanner
Basiert auf: F13 Lizenzscanner
Der Lizenz-Compliance-Scanner basiert auf dem OSS Review Toolkit (ORT) und wurde für die automatisierte Überprüfung aller Software-Abhängigkeiten entwickelt. Er analysiert vollständig den Dependency-Tree von Projekten und identifiziert die Lizenzen aller direkten und transitiven Abhängigkeiten über verschiedene Paketmanager hinweg (NPM, Yarn, PIP, Poetry, Maven, Gradle, Go Modules). Der Scanner ist vollständig in GitLab CI/CD integriert und führt automatisch Compliance-Prüfungen bei Merge Requests oder geplanten Scans durch. Er generiert übersichtliche Berichte, die problematische Lizenzen (proprietär, GPL bei Inkompatibilität) hervorheben und unbekannte Lizenzen zur manuellen Prüfung markieren. Die Lösung unterstützt explizit Proxy-Umgebungen und ist speziell für den Einsatz in Enterprise-Umgebungen konzipiert.
Technologische Basis
Die Referenzimplementierung wurde auf einer modernen Container-Plattform aufgebaut. Dies ermöglicht:
- Einheitliche Verwaltung aller Dienste
- Einfache Skalierung bei wachsenden Anforderungen
- Anbieterunabhängigkeit für flexible Hosting-Optionen
- Automatische Fehlerbehandlung und Wiederherstellung
Der Fokus liegt auf On-Premises-Betrieb in eigener Infrastruktur. Die technische Umsetzung der Referenzarchitektur erfolgte exemplarisch auf Azure, um die Cloud-Agnostik der Kubernetes-Basis zu beweisen. Die Lösung ist jedoch so konzipiert, dass sie beispielsweise mit StackIT, Open Telecom Cloud, IONOS oder anderen Cloud- und On-Premises-Anbietern betrieben werden kann.
Integration und Validierung
Erprobte Anwendungen
Zur Validierung der Plattform wurden verschiedene Anwendungen angebunden:
- Chat-Anwendungen: Test der Konversations-Fähigkeiten
- Fachliche Assistenten: Erprobung spezialisierter Anwendungsfälle
- API-Integration: Validierung der Schnittstellen für Drittsysteme
Netzwerk und Sicherheit
Die Plattform wurde mit verschiedenen Sicherheitskomponenten ausgestattet:
- Verschlüsselte Kommunikation zwischen allen Diensten
- API-Gateway für kontrollierte Zugriffe
- Zertifikatsverwaltung für sichere Verbindungen
- Netzwerksegmentierung für Isolation der Dienste
Veröffentlichte Repositories
Die Referenzimplementierung wird als Open Source veröffentlicht:
- kiva-llm-gateway: Gateway-Implementierung für Modellzugriff
- kiva-vllm: Inferenz-Engine für Modellausführung
- kiva-monitoring: Überwachungslösung mit Dashboards und Alarmierung
- kiva-licensescanner: Lizenz-Compliance-Tool
- kiva.ops: Infrastruktur-Konfiguration und Deployment-Automatisierung
Erkenntnisse und Erfahrungen
Die Referenzimplementierung hat gezeigt:
- Machbarkeit: Eine souveräne KI-Plattform auf Basis von Open Source ist umsetzbar
- Flexibilität: Die modulare Architektur ermöglicht Anpassungen an spezifische Anforderungen
- Skalierbarkeit: Die Plattform kann von Entwicklungsszenarien bis zu produktiven Workloads wachsen
- Komplexität: Der Übergang von der Referenz zur produktionsreifen Lösung erfordert weitere Entwicklung
Ausblick auf Produktivsetzung
Die Referenzimplementierung bildet die Grundlage für eine produktionsreife Plattform. Für den produktiven Einsatz sind jedoch noch weitere Schritte erforderlich, die im Dokument Ausblick auf Produktivsetzung detailliert beschrieben werden.
Wesentliche Aspekte für die Produktivsetzung umfassen:
- Qualitätssicherung: Umfassende Tests und Validierung
- Integration: Anbindung an bestehende IT-Systeme und Prozesse
- Betriebskonzept: Aufbau von Support- und Betriebsorganisation
- Compliance: Erfüllung aller regulatorischen Anforderungen
- Wirtschaftlichkeit: Entwicklung nachhaltiger Betriebsmodelle
Einsatz in deutschen Clouds und souveräner Infrastruktur
Obwohl der aktuelle Proof of Concept (POC) auf dem Azure Kubernetes Service (Westeuropa) betrieben wird, ist die KIVA-Referenzimplementierung strikt Cloud-agnostisch konzipiert. Durch den ausschließlichen Einsatz von Standard-Kubernetes und Helm-Charts bestehen keine Abhängigkeiten zu proprietären Cloud-Diensten oder APIs spezifischer Hyperscaler. Dieses Design ermöglicht den nahtlosen Betrieb in deutschen Verwaltungs-Clouds, On-Premise-Rechenzentren oder Private-Cloud-Umgebungen (z. B. auf Basis von OpenShift). Dies ist essenziell, um die volle Datensouveränität zu gewährleisten und sicherzustellen, dass die Datenverarbeitung ausschließlich in der EU oder in eigenen Rechenzentren gemäß den DSGVO-Vorgaben erfolgt